C Hash Tables & Collision Resolution: Build an O(1) Key-Value Store
Build a complete hash table in C from scratch. Learn hash functions (djb2, FNV-1a, SipHash), collision resolution strategies (chaining vs open addressing), load factor management, and how hash tables power Redis, compiler symbol tables, and database indexes.
C Hash Tables & Collision Resolution: Build an O(1) Key-Value Store
Table of Contents
- The Hash Table Concept: Trading Space for Speed
- Hash Functions: djb2, FNV-1a, and SipHash
- Chaining: Collision Resolution with Linked Lists
- Open Addressing: Linear and Quadratic Probing
- Robin Hood Hashing: Variance Minimization
- Load Factor and Rehashing
- Complete Hash Map Implementation
- Real-World Use Cases
- Performance Analysis: When Hash Tables Fail
- Frequently Asked Questions
- Key Takeaway
The Hash Table Concept: Trading Space for Speed
An array gives you O(1) access by numeric index. A hash table extends this to O(1) access by arbitrary key (string, integer, struct) by using a hash function to convert the key to a numeric index:
The price: extra memory (the array must be larger than the number of items, typically 1.33-2x the load) and complexity (collision handling). For most workloads, this is an excellent trade.
Applications in production systems:
- Redis: All key-value storage uses hash tables; the server-side dict is a resizable hash table.
- Python
dict: Open addressing with random probing; resized at 66% load. - Linux kernel: Symbol tables, filesystem dentry caches, network packet routing tables.
- Compilers: Symbol tables for variable and function name resolution.
- Databases: Hash joins, hash indexes for equality queries.
Hash Functions: djb2, FNV-1a, and SipHash
A hash function converts an arbitrary byte sequence into a fixed-size integer. The ideal properties: fast, uniform distribution (minimizes collisions), and avalanche effect (small input changes produce wildly different outputs).
djb2 (Daniel J. Bernstein)
Simple, fast, historically popular for general string hashing:
#include <stdint.h>
uint64_t hash_djb2(const char *str) {
uint64_t hash = 5381;
int c;
while ((c = (unsigned char)*str++)) {
hash = ((hash << 5) + hash) + c; // hash * 33 + c
}
return hash;
}Pros: Extremely fast (few operations per byte). Cons: Known weaknesses against adversarial inputs (hash flooding attacks).
FNV-1a (Fowler-Noll-Vo)
Excellent distribution with a different formula - preferred for many embedded and systems use cases:
#define FNV_OFFSET_BASIS 14695981039346656037ULL
#define FNV_PRIME 1099511628211ULL
uint64_t hash_fnv1a(const void *data, size_t len) {
uint64_t hash = FNV_OFFSET_BASIS;
const uint8_t *bytes = (const uint8_t*)data;
for (size_t i = 0; i < len; i++) {
hash ^= bytes[i];
hash *= FNV_PRIME;
}
return hash;
}FNV-1a works on arbitrary byte sequences (not just null-terminated strings), making it useful for binary keys.
SipHash (Production Use)
When hash tables accept user-supplied keys (e.g., Python dict, Rust HashMap), a cryptographic hash like SipHash-1-3 provides protection against hash-flooding DoS attacks where an attacker crafts inputs that all hash to the same bucket:
// SipHash is more complex (uses a keyed block cipher internally)
// Python uses SipHash-1-3 by default since Python 3.4
// Use the reference implementation: https://github.com/veorq/SipHashGuideline: For internal, trusted data -> djb2 or FNV-1a. For user-supplied network data -> SipHash.
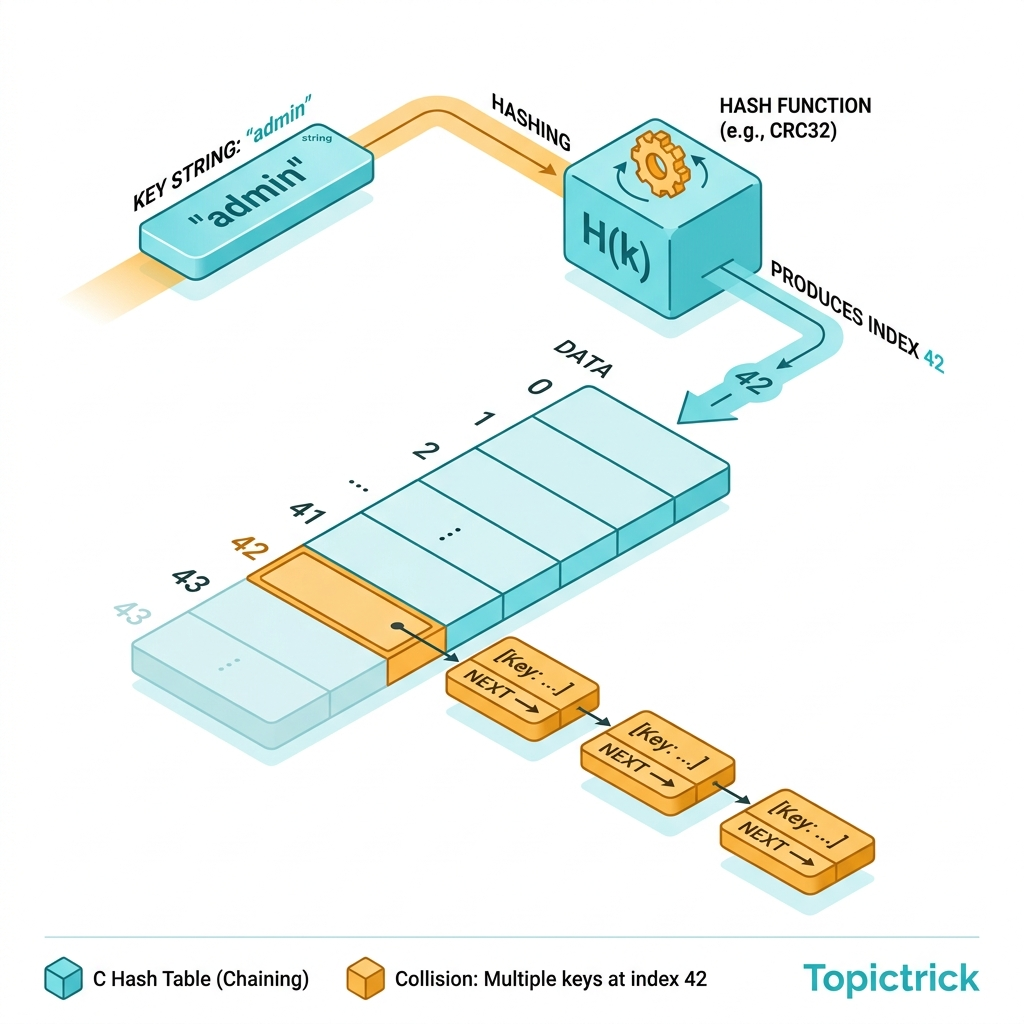
Chaining: Collision Resolution with Linked Lists
In chaining, each slot in the hash table array contains a pointer to a linked list. Colliding entries are added to the list at that slot:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define HT_INITIAL_SIZE 64
typedef struct Entry {
char *key;
char *value;
struct Entry *next; // Linked list chain for collision resolution
} Entry;
typedef struct {
Entry **buckets; // Array of pointers to entry chains
size_t capacity; // Number of buckets
size_t count; // Number of stored items
} HashMap;
// Create a new hash map
HashMap *hm_create(void) {
HashMap *hm = malloc(sizeof(HashMap));
if (!hm) return NULL;
hm->capacity = HT_INITIAL_SIZE;
hm->count = 0;
hm->buckets = calloc(hm->capacity, sizeof(Entry*)); // NULL-init all buckets
if (!hm->buckets) { free(hm); return NULL; }
return hm;
}
// Hash a string key to a bucket index
static size_t hash_to_index(const char *key, size_t capacity) {
uint64_t hash = 5381;
while (*key) {
hash = ((hash << 5) + hash) + (unsigned char)*key++;
}
return (size_t)(hash % capacity);
}
// Insert or update a key-value pair: O(1) average
int hm_set(HashMap *hm, const char *key, const char *value) {
size_t idx = hash_to_index(key, hm->capacity);
// Search for existing key in chain (update if found)
for (Entry *e = hm->buckets[idx]; e != NULL; e = e->next) {
if (strcmp(e->key, key) == 0) {
char *new_val = strdup(value);
if (!new_val) return -1;
free(e->value);
e->value = new_val;
return 0;
}
}
// Key not found - prepend new entry to chain
Entry *entry = malloc(sizeof(Entry));
if (!entry) return -1;
entry->key = strdup(key);
entry->value = strdup(value);
if (!entry->key || !entry->value) {
free(entry->key); free(entry->value); free(entry);
return -1;
}
entry->next = hm->buckets[idx]; // Prepend to chain
hm->buckets[idx] = entry;
hm->count++;
return 0;
}
// Retrieve a value by key: O(1) average, O(n) worst case
const char *hm_get(const HashMap *hm, const char *key) {
size_t idx = hash_to_index(key, hm->capacity);
for (Entry *e = hm->buckets[idx]; e != NULL; e = e->next) {
if (strcmp(e->key, key) == 0) return e->value;
}
return NULL; // Not found
}
// Delete a key: O(1) average
bool hm_delete(HashMap *hm, const char *key) {
size_t idx = hash_to_index(key, hm->capacity);
Entry **current = &hm->buckets[idx];
while (*current) {
Entry *entry = *current;
if (strcmp(entry->key, key) == 0) {
*current = entry->next; // Unlink from chain
free(entry->key);
free(entry->value);
free(entry);
hm->count--;
return true;
}
current = &entry->next;
}
return false;
}
// Free the entire hash map
void hm_destroy(HashMap *hm) {
for (size_t i = 0; i < hm->capacity; i++) {
Entry *e = hm->buckets[i];
while (e) {
Entry *next = e->next;
free(e->key);
free(e->value);
free(e);
e = next;
}
}
free(hm->buckets);
free(hm);
}
int main(void) {
HashMap *hm = hm_create();
hm_set(hm, "name", "Alice");
hm_set(hm, "language", "C");
hm_set(hm, "role", "Systems Engineer");
printf("name: %s\n", hm_get(hm, "name")); // Alice
printf("language: %s\n", hm_get(hm, "language")); // C
printf("missing: %s\n", hm_get(hm, "missing") ?: "(null)");
hm_delete(hm, "role");
hm_destroy(hm);
return 0;
}Open Addressing: Linear and Quadratic Probing
Open addressing stores all entries in the array itself - no linked lists. When a collision occurs, the algorithm probes for an alternative slot:
#include <stdint.h>
#include <string.h>
#include <stdlib.h>
#define OA_SIZE 128
#define DELETED_SENTINEL ((char*)-1) // Tombstone marker
typedef struct {
char *key;
char *value;
} OAEntry;
typedef struct {
OAEntry slots[OA_SIZE];
size_t count;
} OAHashMap;
// Linear probing: if slot i is taken, try i+1, i+2, ...
size_t linear_probe(const OAHashMap *hm, const char *key) {
uint64_t hash = 5381;
while (*key) hash = ((hash << 5) + hash) + (unsigned char)*key++;
size_t idx = (size_t)(hash % OA_SIZE);
while (hm->slots[idx].key != NULL &&
hm->slots[idx].key != DELETED_SENTINEL &&
strcmp(hm->slots[idx].key, key) != 0) {
idx = (idx + 1) % OA_SIZE; // Linear step
}
return idx;
}Linear probing suffers from primary clustering - filled slots cluster together, causing long probe sequences. Quadratic probing (step = i²) and double hashing (step = prime hash) reduce clustering at the cost of complexity.
Robin Hood Hashing: Variance Minimization
Robin Hood hashing is an elegant open addressing variant used by Rust's HashMap and many modern hash table implementations. When inserting a new key, if the existing key at the probe position is richer (closer to its ideal slot) than the inserting key, they swap positions (take from the rich, give to the poor):
// Robin Hood property: each key has a "probe length" = actual_index - ideal_index
// On collision: the key with the longer probe length "steals" the slot
// Result: maximum probe length is O(log n) instead of O(n)
// Advantage: lookup time variance is dramatically reduced - better worst-caseThis gives Robin Hood tables excellent practical performance - used in production by Rust STD, Boost (C++), and many game engines.
Load Factor and Rehashing
The load factor α = count / capacity. As the table fills:
- At α = 0.5: Average chaining list = 0.5 elements, lookup ≈ 1.5 comparisons.
- At α = 0.75 (Python dict): Average ≈ few comparisons, still fast.
- At α = 1.0: Hash table is full - performance degrades to O(n) in worst case.
When α exceeds a threshold (typically 0.75), the table must rehash: allocate a new, larger array (usually 2x the old capacity), then re-insert every existing entry:
int hm_rehash(HashMap *hm) {
size_t new_capacity = hm->capacity * 2;
Entry **new_buckets = calloc(new_capacity, sizeof(Entry*));
if (!new_buckets) return -1;
for (size_t i = 0; i < hm->capacity; i++) {
Entry *entry = hm->buckets[i];
while (entry) {
Entry *next = entry->next;
size_t new_i = hash_to_index(entry->key, new_capacity);
entry->next = new_buckets[new_i];
new_buckets[new_i] = entry;
entry = next;
}
}
free(hm->buckets);
hm->buckets = new_buckets;
hm->capacity = new_capacity;
return 0;
}
// In hm_set, check load before inserting:
if ((double)hm->count / (double)hm->capacity >= 0.75) {
if (hm_rehash(hm) != 0) return -1;
}Rehashing is an O(n) operation, but it happens rarely enough that amortized insertion remains O(1).
Performance Analysis: When Hash Tables Fail
Hash tables are not universally fast. They degrade in several scenarios:
| Problem | Cause | Solution |
|---|---|---|
| Hash flooding attack | Attacker crafts keys that all hash to the same bucket | Use SipHash with secret seed |
| Poor hash function | Keys cluster in a subset of buckets | Use FNV-1a or SipHash |
| Very high load | Too many items for table size | Trigger rehash at α = 0.75 |
| Cache thrashing | Chaining dereferences scattered heap pointers | Use open addressing (more cache-friendly) |
| Key ordering required | Hash tables are unordered | Use a balanced BST (red-black tree) instead |
Frequently Asked Questions
How big should the initial table size be?
Use a power of 2 for bitwise modulo (hash & (capacity - 1) instead of hash % capacity - much faster). A prime number for non-power-of-2 tables reduces certain clustering patterns. Start with 16 or 64 and let rehashing handle growth.
What is a "Tombstone" in open addressing? When you delete a key in open addressing, you can't simply empty the slot - it would break probe chains for other keys that passed through this slot during insertion. Instead, mark it with a tombstone sentinel value. Tombstones are skipped during lookup but counted during insert. Tables with many deletions benefit from periodic compaction.
Why does Python's dict maintain insertion order? CPython 3.7+ uses a combined compact dict with two arrays: a sparse indices array (the hash table proper) and a dense array of key-value pairs in insertion order. This is a more memory-efficient design that naturally preserves insertion order.
When is a hash table worse than a sorted array with binary search? Binary search on a sorted array is O(log n) but has perfect cache locality - every comparison reads adjacent memory. For small tables (< 32 elements), binary search often outperforms hash lookup due to cache efficiency. For large, frequently queried tables, hash lookup consistently wins.
Key Takeaway
Hash Tables represent the pinnacle of Lookup Efficiency - the fundamental data structure that transforms a simple array into an associative container. By mastering hash functions, collision resolution, and load factor management, you gain the ability to build the same kinds of key-value engines that power Redis, the CPython interpreter, and the Linux kernel's dentry cache.
This is not an abstract exercise - every major system software stack uses custom hash table implementations tuned for its specific access patterns. Writing your own from scratch is the only way to truly understand the trade-offs.
Read next: Function Pointers & Callbacks: Event-Driven C ->
Part of the C Mastery Course - 30 modules from fundamentals to expert-level systems engineering.