C++ STL Containers Deep Dive: vector, map, unordered_map, deque, set & Cache Performance
Complete performance guide to C++ STL containers. Understand vector's cache locality advantage, amortized growth cost, reserve() optimization, map vs unordered_map O(log n) vs O(1) tradeoffs, deque chunk structure, flat_map (C++23), container adapters, and how CPU cache lines determine real-world performance of data structures beyond Big-O notation.
C++ STL Containers Deep Dive: vector, map, unordered_map, deque, set & Cache Performance
Table of Contents
- Why Cache Locality Beats Big-O Theory
- Container Selection Decision Tree
- std::vector: Cache-Friendly and Dominant
- vector Growth Strategy and Reserve
- std::array: Stack-Allocated Fixed Sequences
- std::deque: Growing at Both Ends
- std::list and std::forward_list: When Ordered Insertion Wins
- std::map: Sorted Key-Value (Red-Black Tree)
- std::unordered_map: O(1) Hash Table
- std::flat_map (C++23): Sorted Vector Map
- std::set and std::unordered_set
- Container Adapters: stack, queue, priority_queue
- Benchmarking Your Container Choice
- Frequently Asked Questions
Why Cache Locality Beats Big-O Theory
Modern CPUs have cache hierarchies (L1: 32KB, L2: 256KB, L3: 8-32MB) that fetch data in cache lines of 64 bytes. When you access one int in a vector, the CPU fetches the next 15 ints for free (they're in the same cache line). When you access one node in a linked list or tree, the next node is at a random memory address - cache miss, ~100ns penalty:
Benchmark: Iterate 100,000 elements (summing integers)
Performance (lower is better):
std::vector<int> : ~0.06ms ← Fits in cache, SIMD-friendly
std::list<int> : ~2.10ms ← ~35x slower! Random memory, cache miss per node
std::deque<int> : ~0.15ms ← Chunks of contiguous memory
std::map<int, int> keys : ~4.50ms ← Tree traversal = cache miss per nodeThe lesson: For most data sizes (< 1M elements), std::vector outperforms theoretically superior structures because the CPU cache hides the O(n) linear scan cost.
Container Selection Decision Tree
std::vector: Cache-Friendly and Dominant
std::vector<T> stores elements in a contiguous heap buffer. It's the default container for ~90% of C++ use cases:
#include <vector>
#include <algorithm>
std::vector<int> scores;
// push_back: amortized O(1) - may reallocate occasionally
scores.push_back(95);
scores.push_back(82);
scores.push_back(78);
// emplace_back: construct in-place (avoids copy/move)
struct Player { std::string name; int score; };
std::vector<Player> players;
players.emplace_back("Alice", 95); // Constructed directly in vector storage
players.emplace_back("Bob", 82);
// Random access: O(1) - direct pointer arithmetic
int first = scores[0]; // No bounds check (fast, unsafe)
int safe = scores.at(0); // Bounds-checked (throws std::out_of_range)
int back = scores.back(); // Last element - O(1)
// Range operations:
std::sort(scores.begin(), scores.end()); // Sort in-place
auto it = std::find(scores.begin(), scores.end(), 82); // Linear search
// Insert/erase at position - O(n) - must shift elements
scores.insert(scores.begin() + 1, 90); // Insert 90 at index 1
scores.erase(scores.begin() + 2); // Erase index 2
// Iteration:
for (const auto& s : scores) { /* ... */ } // Range-for
for (auto it = scores.begin(); it != scores.end(); ++it) { /* ... */ }
// Raw data access (for C APIs):
int* raw = scores.data(); // Pointer to first element
size_t n = scores.size(); // Number of elementsvector Growth Strategy and Reserve
When push_back exceeds capacity, std::vector reallocates to a new (typically 1.5-2x) larger buffer and moves all elements:
std::vector<int> v;
// Without reserve - multiple reallocations:
// push_back 1-> alloc 1 | push_back 2-> alloc 2+move | push_back 3-> alloc 4+move | ...
// With reserve - ONE allocation:
v.reserve(10000); // Allocate once for expected size
for (int i = 0; i < 10000; i++) {
v.push_back(i); // No reallocations - all in pre-allocated buffer
}
// shrink_to_fit: release excess capacity
v.shrink_to_fit(); // capacity() now equals size()
// swap trick (pre-C++11):
std::vector<int>().swap(v); // Release all memory
v.clear(); // size=0, capacity unchanged (no deallocation)
// Reserve in advance for parser/builder patterns:
std::vector<Token> tokens;
tokens.reserve(source.size() / 3); // Typically 1 token per ~3 chars
parse_into(tokens, source);std::map: Sorted Key-Value (Red-Black Tree)
std::map<K, V> is a balanced binary search tree (red-black tree). Every element is a heap-allocated node - O(log n) for all operations, but significant memory overhead per element:
#include <map>
#include <string>
std::map<std::string, int> word_count;
// Insert:
word_count["hello"]++; // Creates entry with value 0, then increments
word_count.insert({"world", 2});
word_count.emplace("C++", 1);
// Lookup:
auto it = word_count.find("hello");
if (it != word_count.end()) {
std::cout << it->second << '\n'; // 1
}
// Operator[] creates a default entry if missing - careful!
int n = word_count["missing_key"]; // Creates entry with value 0!
auto it2 = word_count.find("missing_key"); // Use find() to avoid creation
// Ordered iteration - alphabetical by key:
for (const auto& [word, count] : word_count) {
std::cout << word << ": " << count << '\n';
}
// Lower/upper bound - range queries (unique to sorted containers):
auto lb = word_count.lower_bound("h"); // First key >= "h"
auto ub = word_count.upper_bound("m"); // First key > "m"
for (auto it = lb; it != ub; ++it) {
std::cout << it->first << '\n'; // All keys between "h" and "m"
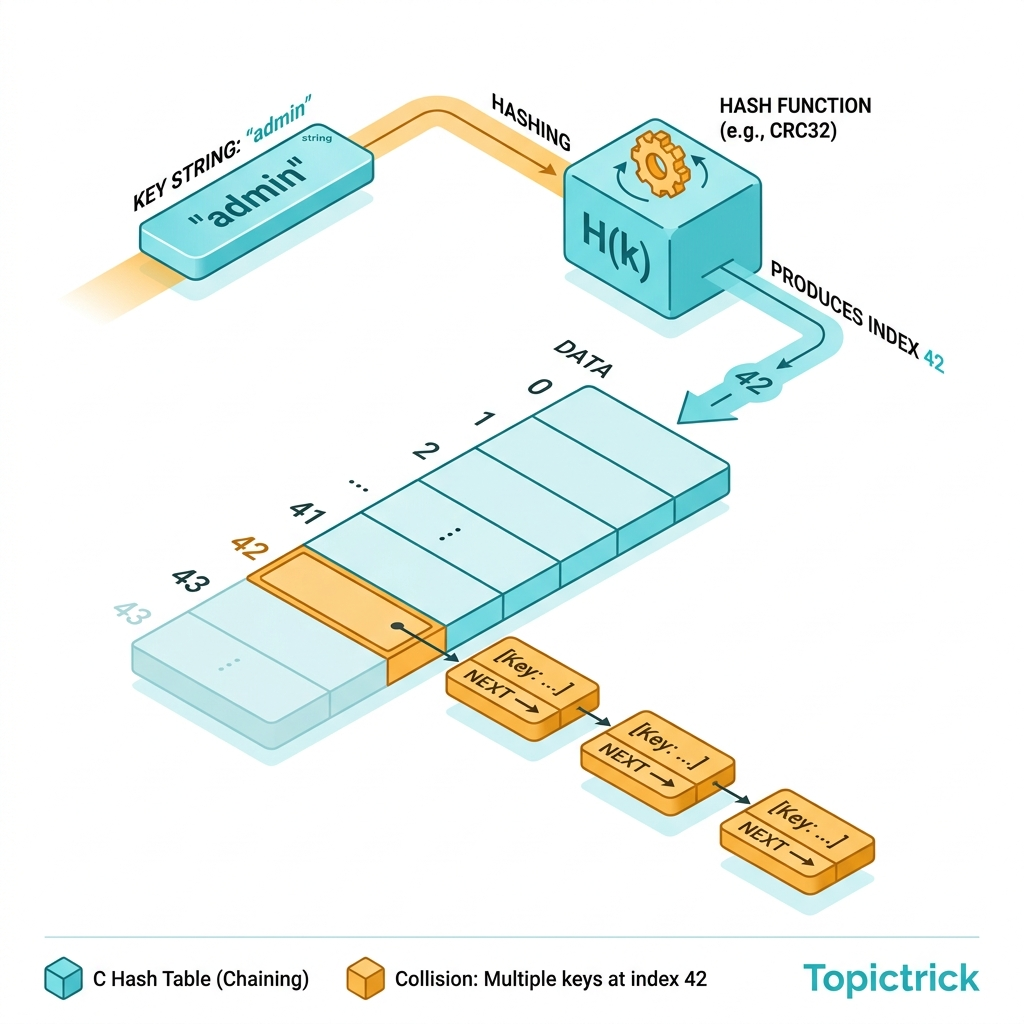
}std::unordered_map: O(1) Hash Table
std::unordered_map<K, V> provides O(1) average lookup but no ordering, larger memory overhead (bucket array), and potential O(n) worst case on hash collisions:
#include <unordered_map>
std::unordered_map<std::string, int> cache;
// Reserve buckets to avoid rehashing (analogous to vector::reserve):
cache.reserve(1000); // Reserve space for 1000 elements
cache.max_load_factor(0.75f); // Rehash when 75% full (default)
// Same API as std::map for basic operations:
cache["key1"] = 42;
cache.emplace("key2", 100);
if (auto it = cache.find("key1"); it != cache.end()) {
std::cout << it->second << '\n';
}
// Custom hash for your types:
struct Point { int x, y; };
struct PointHash {
size_t operator()(const Point& p) const {
// Combine hashes (Boost hash_combine technique):
size_t h1 = std::hash<int>{}(p.x);
size_t h2 = std::hash<int>{}(p.y);
return h1 ^ (h2 << 32 | h2 >> 32);
}
};
struct PointEqual {
bool operator()(const Point& a, const Point& b) const {
return a.x == b.x && a.y == b.y;
}
};
std::unordered_map<Point, std::string, PointHash, PointEqual> point_names;
point_names[{0, 0}] = "Origin";
point_names[{1, 0}] = "X-axis";std::flat_map (C++23): Sorted Vector Map
std::flat_map (C++23) implements a sorted map using two contiguous vectors (keys and values) instead of a tree. Cache-friendly iteration, but O(n) insert:
#include <flat_map> // C++23
// Better than std::map when: many lookups, few insertions, cache matters
std::flat_map<int, std::string> fm;
fm.insert({1, "one"});
fm.insert({3, "three"});
fm.insert({2, "two"});
// Keys are sorted: 1, 2, 3
for (auto [k, v] : fm) std::cout << k << ": " << v << '\n';
// Build from sorted data: O(n log n) - vector-of-pairs approach:
std::vector<std::pair<int, std::string>> data = {{1,"a"},{2,"b"},{3,"c"}};
std::flat_map<int, std::string> fm2(std::from_range, data);
// flat_map vs map benchmark (read-heavy, 10,000 elements):
// std::map lookup: ~150ns (cache miss per node)
// std::flat_map lookup: ~20ns (binary search on contiguous array)
// std::unordered_map lookup: ~10ns (hash, O(1) average)Container Adapters: stack, queue, priority_queue
#include <stack>
#include <queue>
// stack<T>: LIFO - wraps deque by default, can use vector
std::stack<int> undo_stack;
undo_stack.push(1);
undo_stack.push(2);
int top = undo_stack.top(); // 2 - peek without removing
undo_stack.pop(); // Remove top
// stack with vector backend (more cache friendly):
std::stack<int, std::vector<int>> fast_stack;
// queue<T>: FIFO - task queue, BFS
std::queue<std::string> task_queue;
task_queue.push("task1");
task_queue.push("task2");
std::string next = task_queue.front(); // "task1"
task_queue.pop();
// priority_queue<T>: max-heap by default (largest element first)
std::priority_queue<int> pq;
pq.push(5); pq.push(1); pq.push(8);
std::cout << pq.top() << '\n'; // 8 (max)
// Min-heap:
std::priority_queue<int, std::vector<int>, std::greater<int>> min_pq;
min_pq.push(5); min_pq.push(1); min_pq.push(8);
std::cout << min_pq.top() << '\n'; // 1 (min)Frequently Asked Questions
When should I use std::list over std::vector?
Almost never in practice. Despite O(1) mid-insertion in theory, std::list suffers from cache misses on every element access. Benchmarks consistently show std::vector winning for iteration-heavy workloads even with O(n) insertion, because L1/L2 cache prefetching hides the shift cost. Use std::list only when you have hard requirements: stable iterators that must survive insertions, or genuinely need O(1) splice operations between lists.
Why does std::unordered_map sometimes perform worse than std::map? Hash collisions degrade unordered_map to O(n) worst case. Additionally, the hash bucket array has worse cache locality than a tree for small maps (< 64 elements). A third issue: hashing strings involves processing every character - for very short keys, map's string comparison can be faster than hashing. Always benchmark with your real data distribution.
What's the memory overhead of each container?
std::vector: 3 pointers (24 bytes) + contiguous data. Most efficient.std::map/set: 3 pointers per node (24 bytes overhead per element). ~3-4x more memory than vector.std::unordered_map: bucket array + per-element linked list nodes. ~5-6x more memory than vector.std::flat_map: two vectors - similar to vector overhead, most memory-efficient for sorted maps.
Part of the C++ Mastery Course - 30 modules from modern C++ basics to expert systems engineering.