Project: Building a Low-Latency LRU Cache Engine in C (Hash Table + Doubly Linked List)
Phase 3 Capstone project. Build a production-quality LRU cache combining a hash table for O(1) lookup with a doubly linked list for O(1) eviction ordering. Implements generic void* values, thread-safe concurrent access, TTL expiration, cache statistics, and the exact design used by Redis, Memcached, and CPU L1/L2 caches.
Project: Building a Low-Latency LRU Cache Engine in C (Hash Table + Doubly Linked List)
Phase 3 Capstone. After mastering hash tables and doubly linked lists, you'll combine them into their most powerful combined form: an LRU (Least Recently Used) cache. This data structure achieves O(1) get, O(1) put, and O(1) eviction simultaneously - the exact engine inside Redis, Memcached, your CPU's L1/L2 cache controller, and Linux's page cache.
Table of Contents
- Why LRU? The Cache Locality Principle
- Architecture: The Hybrid Data Structure
- Node and Cache Structure Design
- Doubly Linked List Operations
- Hash Table Integration
- cache_get: O(1) Lookup + Promote
- cache_put: O(1) Insert + Auto-Evict
- Thread-Safe LRU with Mutex
- TTL Expiration: Time-Based Eviction
- Cache Statistics and Hit Ratio
- Extension Challenges
- Phase 3 Reflection
Why LRU? The Cache Locality Principle
Caches work because of temporal locality: recently accessed data is likely to be accessed again soon. LRU approximates the optimal eviction strategy:
- 80% of requests typically hit 20% of data items (Pareto principle).
- The "least recently used" item is the safest to evict - we have evidence it's not hot.
- LRU maintains a running model of "hotness" with O(1) operations.
Architecture: The Hybrid Data Structure
| Operation | Array | Linked List | Hash Table | LRU (Hash+List) |
|---|---|---|---|---|
get(key) | O(n) | O(n) | O(1) avg | O(1) |
put(key) | O(1) | O(1) | O(1) avg | O(1) |
evict LRU | O(n) | O(1) | N/A | O(1) |
| Ordered? | ❌ | ✅ | ❌ | ✅ |
The magic: the hash table stores pointers to nodes in the linked list. Finding a node by key is O(1) via the hash table. Promoting or evicting a node is O(1) via doubly linked list pointer manipulation. Neither data structure alone achieves all three in O(1).
Node and Cache Structure Design
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#include <stdint.h>
#include <pthread.h>
#include <time.h>
#define MAX_KEY_LEN 128
#define HT_CAPACITY 4096
typedef struct LRUNode {
char key[MAX_KEY_LEN]; // Hash map key
void *value; // Generic value (any type)
size_t value_size; // Size of value in bytes
int64_t expires_at; // Unix timestamp, or -1 if no TTL
struct LRUNode *prev; // Towards MRU (head)
struct LRUNode *next; // Towards LRU (tail)
struct LRUNode *ht_next; // Hash table collision chain
} LRUNode;
typedef struct {
LRUNode **buckets; // Hash table array of collision chains
LRUNode *head; // MRU end of list (most recently used)
LRUNode *tail; // LRU end of list (eviction target)
size_t capacity; // Maximum number of entries
size_t count; // Current number of entries
// Statistics
uint64_t hits;
uint64_t misses;
uint64_t evictions;
pthread_mutex_t lock; // Thread safety
} LRUCache;Doubly Linked List Operations
These O(1) operations are the heart of LRU's constant-time performance:
// Remove a node from the doubly linked list
static void list_remove(LRUCache *cache, LRUNode *node) {
if (node->prev) node->prev->next = node->next;
else cache->head = node->next; // Was head
if (node->next) node->next->prev = node->prev;
else cache->tail = node->prev; // Was tail
node->prev = node->next = NULL;
}
// Insert a node at the HEAD (MRU position)
static void list_push_head(LRUCache *cache, LRUNode *node) {
node->prev = NULL;
node->next = cache->head;
if (cache->head) cache->head->prev = node;
else cache->tail = node; // Empty list
cache->head = node;
}
// Move an existing node to the HEAD (after access - "promote")
static void list_promote(LRUCache *cache, LRUNode *node) {
if (node == cache->head) return; // Already MRU - nothing to do
list_remove(cache, node);
list_push_head(cache, node);
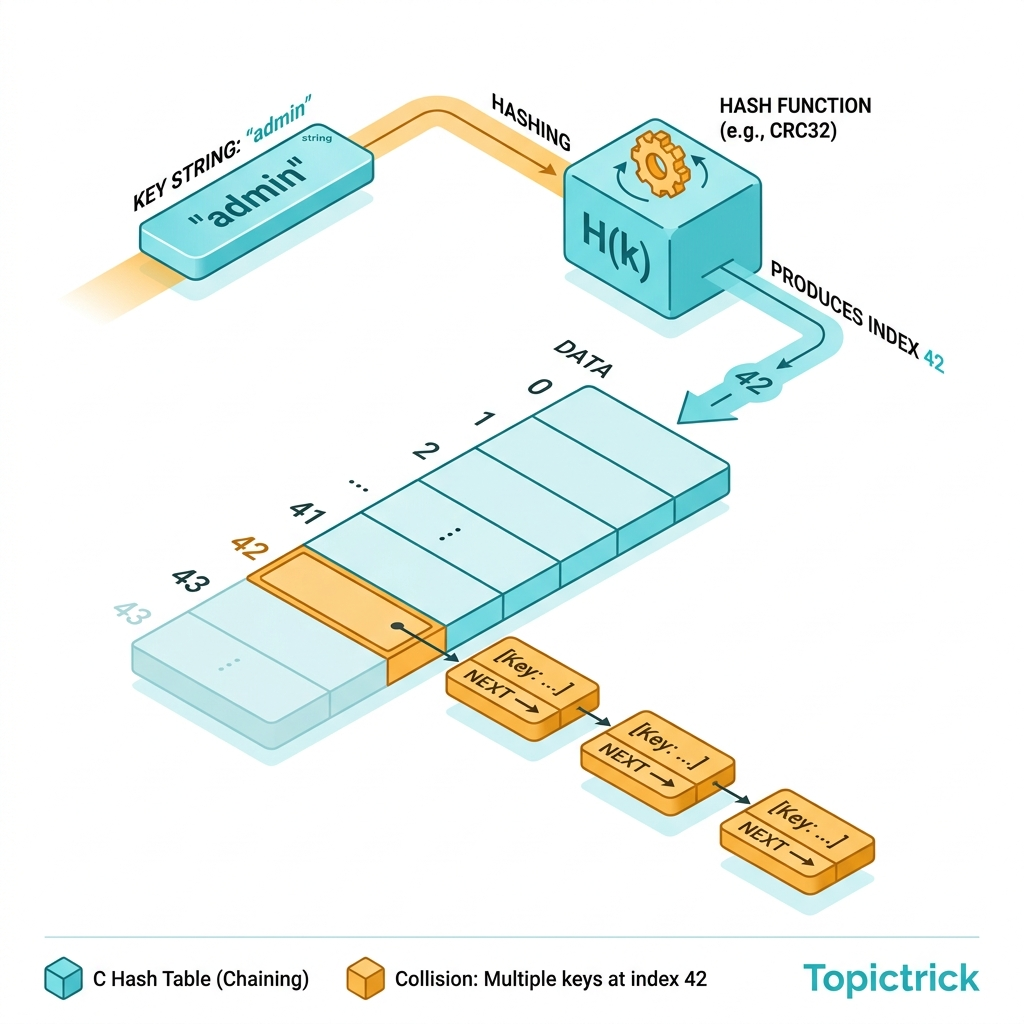
}Hash Table Integration
// djb2 hash function
static uint32_t hash_key(const char *key) {
uint32_t hash = 5381;
unsigned char c;
while ((c = (unsigned char)*key++)) {
hash = ((hash << 5) + hash) + c;
}
return hash;
}
// Look up a node in the hash table
static LRUNode* ht_find(LRUCache *cache, const char *key) {
uint32_t bucket = hash_key(key) % HT_CAPACITY;
LRUNode *node = cache->buckets[bucket];
while (node) {
if (strcmp(node->key, key) == 0) return node;
node = node->ht_next;
}
return NULL;
}
// Insert a node into the hash table
static void ht_insert(LRUCache *cache, LRUNode *node) {
uint32_t bucket = hash_key(node->key) % HT_CAPACITY;
node->ht_next = cache->buckets[bucket];
cache->buckets[bucket] = node;
}
// Remove a node from the hash table
static void ht_remove(LRUCache *cache, const char *key) {
uint32_t bucket = hash_key(key) % HT_CAPACITY;
LRUNode **ptr = &cache->buckets[bucket];
while (*ptr) {
if (strcmp((*ptr)->key, key) == 0) {
*ptr = (*ptr)->ht_next;
return;
}
ptr = &(*ptr)->ht_next;
}
}cache_get: O(1) Lookup + Promote
// Get a value by key. Returns the value pointer or NULL on miss/expiration.
void* cache_get(LRUCache *cache, const char *key) {
pthread_mutex_lock(&cache->lock);
LRUNode *node = ht_find(cache, key);
if (!node) {
cache->misses++;
pthread_mutex_unlock(&cache->lock);
return NULL; // Cache miss
}
// Check TTL expiration
if (node->expires_at > 0 && time(NULL) > node->expires_at) {
// Entry expired - remove it
ht_remove(cache, key);
list_remove(cache, node);
free(node->value);
free(node);
cache->count--;
cache->misses++;
pthread_mutex_unlock(&cache->lock);
return NULL;
}
// Cache hit - promote to MRU position
list_promote(cache, node);
cache->hits++;
void *value = node->value;
pthread_mutex_unlock(&cache->lock);
return value;
}cache_put: O(1) Insert + Auto-Evict
// Put a key-value pair. Evicts LRU item if at capacity.
// value is copied - caller retains ownership of the original
int cache_put(LRUCache *cache, const char *key, const void *value,
size_t value_size, int ttl_seconds) {
pthread_mutex_lock(&cache->lock);
// Check if key already exists - update in place
LRUNode *existing = ht_find(cache, key);
if (existing) {
free(existing->value);
existing->value = malloc(value_size);
if (!existing->value) { pthread_mutex_unlock(&cache->lock); return -1; }
memcpy(existing->value, value, value_size);
existing->value_size = value_size;
existing->expires_at = ttl_seconds > 0 ? time(NULL) + ttl_seconds : -1;
list_promote(cache, existing);
pthread_mutex_unlock(&cache->lock);
return 0;
}
// Evict LRU item if at capacity
if (cache->count >= cache->capacity) {
LRUNode *lru = cache->tail; // The least recently used
if (lru) {
ht_remove(cache, lru->key);
list_remove(cache, lru);
free(lru->value);
free(lru);
cache->count--;
cache->evictions++;
}
}
// Create new node
LRUNode *node = malloc(sizeof(LRUNode));
if (!node) { pthread_mutex_unlock(&cache->lock); return -1; }
strncpy(node->key, key, MAX_KEY_LEN - 1);
node->key[MAX_KEY_LEN - 1] = '\0';
node->value = malloc(value_size);
if (!node->value) { free(node); pthread_mutex_unlock(&cache->lock); return -1; }
memcpy(node->value, value, value_size);
node->value_size = value_size;
node->expires_at = ttl_seconds > 0 ? time(NULL) + ttl_seconds : -1;
node->ht_next = node->prev = node->next = NULL;
ht_insert(cache, node);
list_push_head(cache, node);
cache->count++;
pthread_mutex_unlock(&cache->lock);
return 0;
}Cache Statistics and Hit Ratio
typedef struct {
uint64_t hits;
uint64_t misses;
uint64_t evictions;
size_t count;
size_t capacity;
double hit_ratio; // hits / (hits + misses)
} CacheStats;
CacheStats cache_get_stats(LRUCache *cache) {
pthread_mutex_lock(&cache->lock);
CacheStats stats = {
.hits = cache->hits,
.misses = cache->misses,
.evictions = cache->evictions,
.count = cache->count,
.capacity = cache->capacity,
.hit_ratio = (cache->hits + cache->misses) > 0 ?
(double)cache->hits / (cache->hits + cache->misses) : 0.0,
};
pthread_mutex_unlock(&cache->lock);
return stats;
}
void cache_print_stats(LRUCache *cache) {
CacheStats s = cache_get_stats(cache);
printf("Cache Stats: %zu/%zu entries | Hits: %llu | Misses: %llu | "
"Hit ratio: %.1f%% | Evictions: %llu\n",
s.count, s.capacity, s.hits, s.misses, s.hit_ratio * 100, s.evictions);
}Extension Challenges
- LFU (Least Frequently Used) Cache: Track access count per node; evict the node with the lowest count. More complex but better hit ratio for certain workloads.
- Two-Queue (2Q) Cache: Separate "hot" and "warm" queues - new items enter warm, move to hot on second access. Mimics adaptive cache behavior.
- CLOCK algorithm: Instead of a doubly linked list, use a circular buffer with access bits - lower memory overhead for very large caches.
- Sharded LRU: Partition the key space into N independent LRU caches, each with its own mutex - eliminates the single global lock as a concurrency bottleneck.
- Persistence: On
cache_destroy, serialize all entries to binary file withfwrite; reload oncache_initto restore hot data across restarts.
Phase 3 Reflection
Building an LRU cache is the systems programmer's rite of passage. You've moved from "writing C code" to "designing data structures where the choice of operations determines which algorithmic complexity class is possible."
This understanding - that data structure design constrains algorithmic performance more than algorithmic cleverness - is the defining insight that separates systems engineers from general-purpose programmers. Redis, Memcached, and every major CDN are built on variations of this exact pattern.
Read next: Phase 4: Concurrency & Networking ->
Frequently Asked Questions
Q: What data structures implement an LRU cache efficiently in C?
An LRU cache needs O(1) lookup and O(1) eviction of the least-recently-used entry. The classic solution combines a hash table (for O(1) key lookup) with a doubly-linked list (for O(1) move-to-front and tail removal). On cache hit: find the node via the hash table, unlink it from its current position, and move it to the list head. On cache miss: if full, remove the tail node (LRU entry) and its hash table entry, then insert the new node at the head. In C, implement the hash table as an array of buckets with chaining using struct nodes that carry both hash-chain and LRU-list pointers.
Q: How do you handle hash collisions in the hash table component of a C LRU cache?
Use separate chaining - each hash bucket is a linked list of entries that hash to the same bucket index. On lookup, hash the key to find the bucket, then linearly scan the chain for an exact key match using strcmp() (for string keys) or memcmp(). Keep chains short by choosing a good hash function (FNV-1a or djb2 work well for strings) and a load factor below 0.75 - resize the table when count / buckets > 0.75 by doubling bucket count and rehashing all entries.
Q: What are the practical applications of an LRU cache in systems programming? LRU caches appear in: CPU TLBs and page replacement algorithms (OS memory management), database buffer pools (keeping hot pages in RAM), DNS resolvers (caching recent lookups), web proxies (caching frequent responses), and compiled language runtimes (caching JIT-compiled code). In application code, wrapping expensive function calls - database queries, API requests, file reads - in an LRU cache with a sensible capacity and TTL can reduce latency by orders of magnitude for repeated access patterns.
Part of the C Mastery Course - 30 modules from C basics to expert systems engineering.