Choosing the Right Software Architecture: A Decision Guide for Developers
Master the decision. Learn the framework for choosing between Monoliths, Microservices, and Event-Driven designs based on your team, budget, and goals.
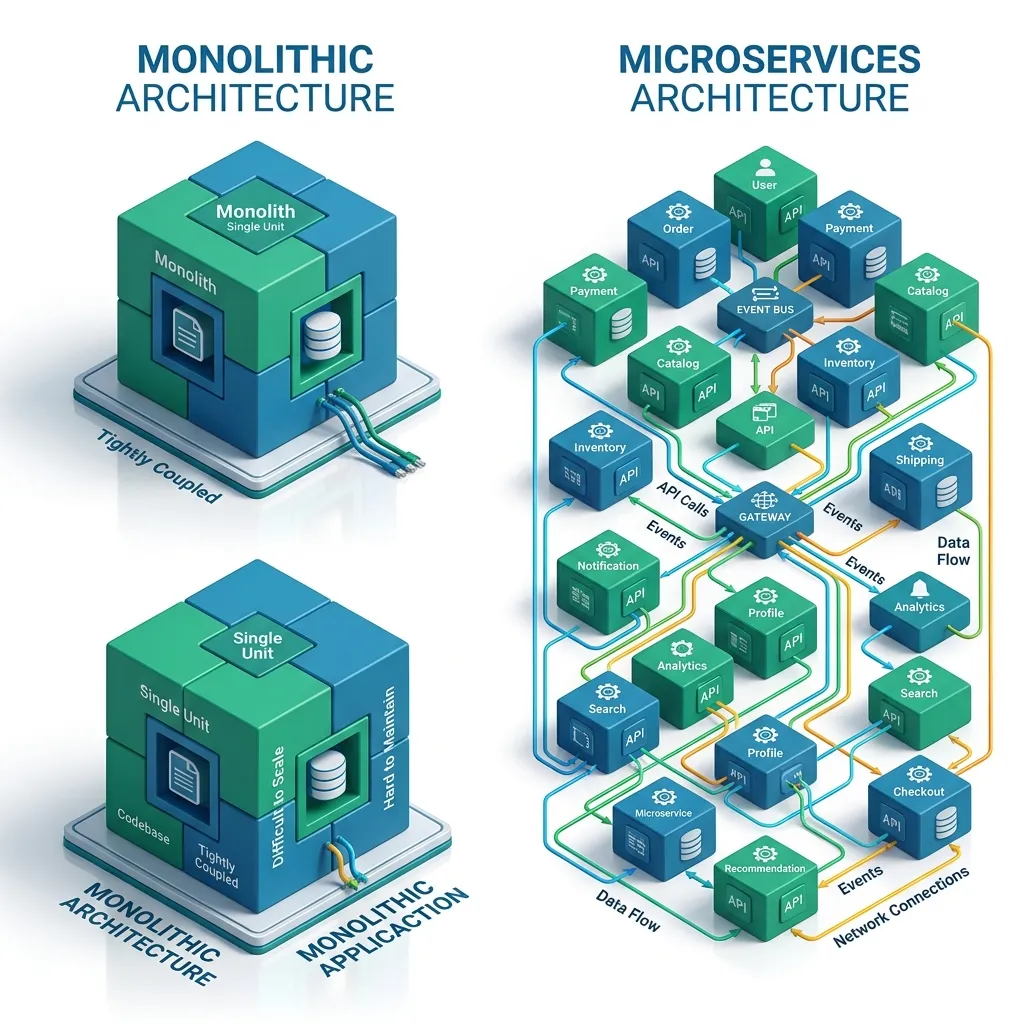
Choosing the Right Software Architecture: A Decision Guide
Picking the wrong architecture is one of the most expensive mistakes in software engineering. Teams that start with microservices before they understand their domain end up with distributed monoliths - all the complexity of distributed systems with none of the benefits. Teams that stay in a tangled monolith too long miss the ability to scale independently or move quickly across dozens of engineers.
This guide gives you a concrete decision framework: five questions that map to architectural choices, a detailed comparison of the major patterns with real trade-offs, and guidance on how to evolve your architecture as your product and organisation grow.
The Core Trade-off
Every architecture choice is a bet about what constraints will matter most:
| Constraint | Favours |
|---|---|
| Speed of early development | Monolith |
| Independent team scaling | Microservices |
| Independent component scaling | Microservices / Serverless |
| Strong data consistency | Monolith / Modular Monolith |
| Decoupled team autonomy | Event-Driven Architecture |
| Zero DevOps budget | Monolith on PaaS |
| Cost at variable traffic | Serverless |
| Long-term maintainability | Modular Monolith -> Microservices |
No architecture is universally superior. The right choice depends on your specific team size, domain complexity, traffic characteristics, and operational budget.
The Five Questions
Work through these questions in order. Most decisions resolve at question 2 or 3:
Question 1: How large is your team?
< 5 engineers -> Monolith (communication overhead of microservices exceeds the benefit)
5-15 engineers -> Modular Monolith (team can grow into services when boundaries are clear)
15-50 engineers -> Modular Monolith or first selective extractions
> 50 engineers -> Multiple services aligned to team boundaries (Conway's Law applies)Conway's Law: systems tend to mirror the communication structure of the organisation that builds them. A 3-person team trying to maintain 15 microservices will produce 15 tightly-coupled microservices that break in concert. A 100-person organisation that keeps everything in one monolith will produce a monolith with hidden couplings everywhere.
Question 2: How well do you understand your domain?
You understand the domain (clear bounded contexts, stable data model, predictable feature roadmap):
- Microservices boundaries are safe to define
- Premature extraction is manageable because you know where lines should be
You are exploring the domain (new product, frequent pivots, uncertain data model):
- A monolith lets you refactor across the entire codebase easily
- Extracting microservices from a wrong boundary requires distributed system surgery
- Rule: do not extract until the boundary has been stable for 6+ months
Question 3: What are your scaling bottlenecks?
Uniform traffic, no single hot component -> Scale the whole monolith horizontally
One specific component dominates CPU/IO -> Extract that component to a service
Unpredictable spikes on specific functions -> Serverless for those functions
Extreme global scale (millions req/sec) -> Distributed architecture with CDN edgeMost applications never reach the scale where a monolith becomes the bottleneck. Instagram, GitHub, Shopify, and Stack Overflow all ran as monoliths at tens of millions of users.
Question 4: What is your operational budget?
Microservices require significantly more operational investment:
| Operational need | Monolith | Microservices |
|---|---|---|
| Deployment pipeline | 1 pipeline | 1 per service (5-50+) |
| Service discovery | Not needed | Required |
| Distributed tracing | Optional | Essential |
| API gateway | Optional | Required |
| Container orchestration | Optional | Usually required |
| On-call complexity | Single failure domain | Multiple cascading failure domains |
Rule of thumb: microservices require at least one dedicated platform/DevOps engineer. If your team has no one focused on infrastructure, the operational burden will slow feature development to a crawl.
Question 5: What are your data consistency requirements?
Financial transactions, inventory management, ACID operations
-> Monolith with a single relational database is far simpler
-> Distributed transactions (sagas) in microservices are complex and error-prone
Independent data domains, acceptable eventual consistency
-> Database-per-service in microservices is safe
-> Event-driven integration between services works well
Real-time analytics separate from OLTP
-> CQRS: separate read/write models, event-sourced write sideArchitecture Patterns at Each Stage
Stage 1: The Modular Monolith (0 to Product-Market Fit)
A single deployable unit where modules are strictly separated by code boundaries, not network boundaries.
my-app/
+-- modules/
| +-- users/
| | +-- users.controller.ts
| | +-- users.service.ts
| | +--- users.repository.ts
| +-- orders/
| | +-- orders.controller.ts
| | +-- orders.service.ts
| | +--- orders.repository.ts
| +--- payments/
| +-- payments.controller.ts
| +-- payments.service.ts
| +--- payments.repository.ts
+--- shared/
+-- database/
+--- auth/Strict rule: modules communicate only through defined interfaces, never by importing each other's internal files.
// Good: modules communicate through service interfaces
import { OrdersService } from '../orders/orders.service';
// Bad: reaching into another module's internals
import { OrderRepository } from '../orders/orders.repository';This internal discipline means you can extract a module to a separate service later without a rewrite - the interface is already defined.
When to stay here: You are under 20 engineers, your domain is not fully understood, or you cannot afford microservices operational overhead.
Stage 2: Selective Extraction (Growth Phase)
Extract only the component with a genuine scaling problem or a team ownership problem. Keep everything else in the monolith.
my-app (monolith) video-processor (microservice)
+-- users +-- Processes video uploads
+-- orders +-- Runs on GPU instances
+-- payments +--- Called via async queue
+--- notifications
|
+----> Publishes to SQS -> video-processor consumesThe "strangler fig" pattern: the monolith handles everything initially. New capabilities that need independent scaling grow as separate services. The monolith shrinks over time as more slices are extracted.
// Monolith publishes an event - doesn't know who processes it
await sqs.send(new SendMessageCommand({
QueueUrl: process.env.VIDEO_PROCESSING_QUEUE,
MessageBody: JSON.stringify({
videoId,
userId,
s3Key: upload.key
})
}));Stage 3: Event-Driven Architecture (Organisational Scale)
When you have multiple teams that need to work independently without coordinating API changes, move to event-driven integration:
Order Service -> publishes OrderPlaced event to Kafka
+-- Inventory Service consumes -> reserves stock
+-- Payment Service consumes -> charges card
+-- Notification Service consumes -> sends confirmation email
+--- Analytics Service consumes -> records funnel eventNo service calls another service's API directly. Each publishes events and reacts to events. Teams can add new consumers without changing the producer.
// Order Service - publishes and forgets
await kafka.send({
topic: 'order-events',
messages: [{
key: orderId,
value: JSON.stringify({
type: 'OrderPlaced',
orderId,
userId,
items,
totalAmount,
timestamp: new Date().toISOString()
})
}]
});Trade-off: Event-driven systems are harder to debug and reason about. Use distributed tracing (OpenTelemetry) and keep a correlation ID in every event.
Architecture Decision Record Template
Document every significant architecture decision:
# ADR-001: Use Modular Monolith for Initial Launch
## Status: Accepted - 2026-01-15
## Context
We have a 4-person engineering team launching a new SaaS product. The domain
model is not yet stable. We have no dedicated DevOps engineer. Time-to-market
is the primary constraint.
## Decision
Build a modular monolith in NestJS with strict module boundaries. Deploy to
Render.com as a single Node.js service backed by PostgreSQL.
## Alternatives Considered
- Microservices: rejected - no DevOps capacity, domain not understood yet
- Serverless: rejected - relational data model requires persistent connections
- Event-Driven: rejected - premature for current team size and scale
## Consequences
- Development speed maximised for small team
- Horizontal scaling limited to single service (acceptable for <100k users)
- Module boundaries enforced through ESLint import rules
- Revisit when team grows past 10 engineers or specific scaling bottleneck identified
## Review Date: 2026-07-15Common Architecture Anti-Patterns
The Distributed Monolith: Microservices that must be deployed together, share a database, or fail together. You have the operational cost of microservices with none of the benefits. Signs: services call each other synchronously in a chain; deploying one service requires deploying others; a bug in Service A consistently breaks Service B.
The Premature Optimisation: Building for 10 million users before you have 10,000. Event-driven Kafka architecture, Kubernetes, service mesh - all before you understand what your product actually needs. Signs: team of 5 managing 30 services; build times measured in hours; most engineers spending more time on infrastructure than features.
The Monolith That Grew: A modular monolith where the module boundaries were never enforced. Every module imports from every other module. There is no way to extract a service without untangling years of hidden coupling. Signs: changing one model breaks unrelated tests; no engineer understands the full dependency graph.
Frequently Asked Questions
Q: Should I start with microservices to avoid having to migrate later?
No. Starting with microservices before you understand your domain boundaries is the most common cause of costly re-architectures. Domain boundaries that seem obvious early often turn out to be wrong once the product evolves. It is significantly easier to extract services from a well-structured monolith than to merge incorrectly split microservices. Build a modular monolith, enforce strict boundaries, and extract when you have a clear, stable boundary and a real scaling or team-ownership reason.
Q: When is serverless the right architecture choice?
Serverless (AWS Lambda, Cloudflare Workers) is the right choice for: event-triggered processing (image resizing, document conversion), variable traffic with long idle periods (cost optimisation), simple APIs that do not need persistent connections, and edge computation where latency to the nearest data centre matters. Serverless is a poor fit for: latency-sensitive applications that cannot absorb cold start times, long-running jobs, and complex stateful workloads.
Q: What is the Strangler Fig pattern and when should I use it?
The Strangler Fig pattern migrates a monolith to services incrementally. New functionality is built as separate services from the start. Existing functionality is extracted to services one piece at a time, with the monolith gradually shrinking. An API gateway routes traffic to either the monolith or the new service. Use this when migrating a production system that cannot be rewritten entirely - it minimises risk by allowing incremental migration with rollback at each step.
Q: How do I choose between REST and event-driven communication between services?
Use synchronous REST when: the caller needs an immediate response to proceed, the operation is user-facing and latency matters, or the interaction is simple request-response. Use asynchronous events when: the producer does not need to know who consumes the result, the operation can tolerate processing delay, or you want to decouple teams so they can evolve independently. Most systems use both: REST for user-facing reads and writes, events for downstream side-effects (notifications, analytics, inventory updates).
Key Takeaway
Architecture selection is a decision about which constraints matter most for your specific situation. Start with the five questions - team size, domain understanding, scaling bottlenecks, operational budget, and data consistency needs. Most teams should begin with a modular monolith, enforce strict internal boundaries, and extract services only when a clear problem (scaling, team ownership, or reliability isolation) justifies the operational cost. Document every significant architectural decision with an ADR so future engineers understand not just what was chosen, but why.
Part of the Software Architecture Hub - engineering the right choice.