Service Mesh vs. API Gateway vs. Sidecar: The Networking Tax
Master the distinction between edge traffic and service-to-service communication. Learn when to use a Service Mesh, why API Gateways are the first line of defense, and the physical CPU cost of the sidecar proxy.
Service Mesh vs. API Gateway vs. Sidecar: The Networking Tax
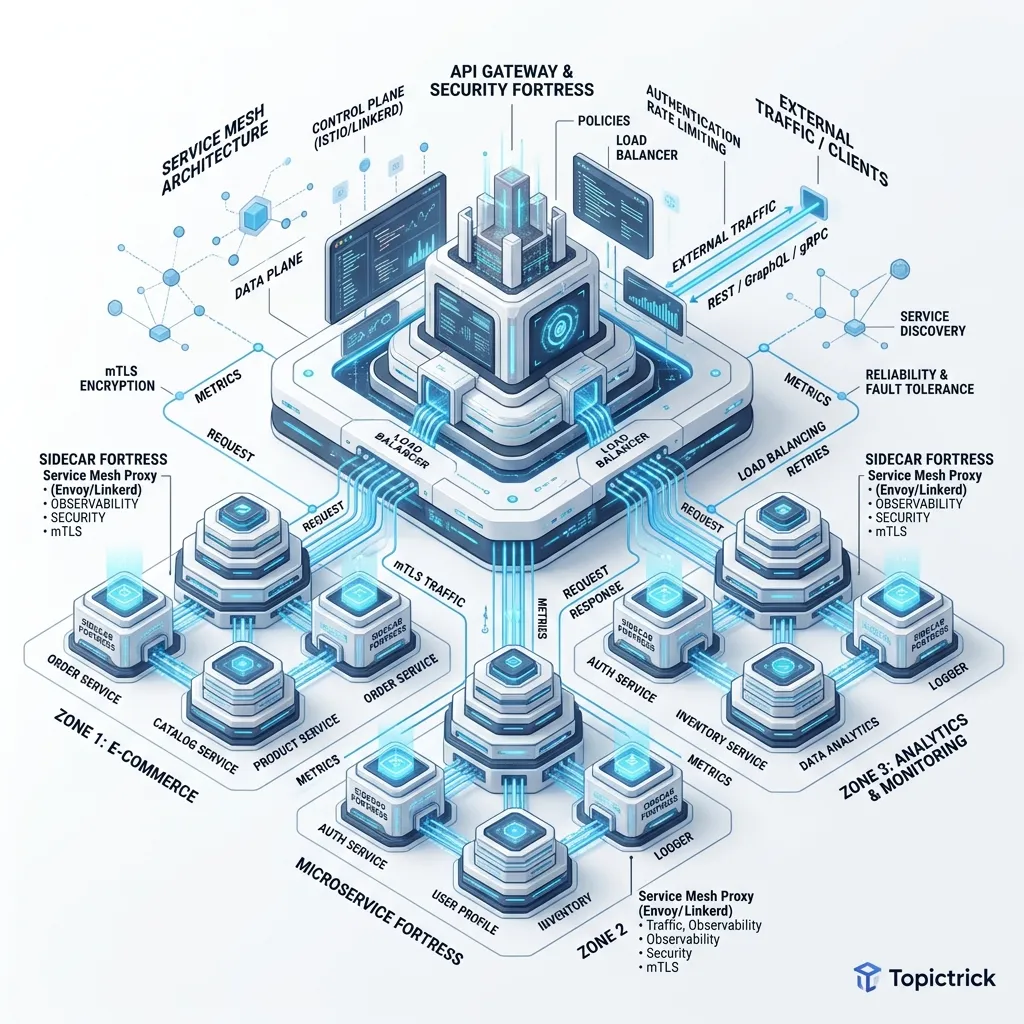
As microservice ecosystems grow from 10 to 100+ services, the complexity of managing communication becomes the primary inhibitor of velocity. Architects often find themselves caught in a confusing debate: "Do we need an API Gateway or a Service Mesh?" The answer is almost always both, but for different reasons.
This 1,500+ word deep dive investigates the Physical Reality of Network Proxies. We move beyond the YAML configuration and explore the silicon-level overhead of moving bits between services in a Zero Trust environment.
1. The Functional Split: North-South vs. East-West
To understand these tools, we must first categorize our traffic flows based on their directionality.
North-South Traffic (The API Gateway)
This is traffic flowing from the outside world (the internet, mobile apps) into your internal network.
- Goal: Edge Defense and Consumer Experience.
- Key Features: Authentication (OIDC), Rate Limiting, Request Transformation, and Monetization.
East-West Traffic (The Service Mesh)
This is traffic flowing between your internal services (e.g., OrderService calling PaymentService).
- Goal: Resilience, Observability, and Fine-Grained Security.
- Key Features: Mutual TLS (mTLS), Retries, Circuit Breaking, and internal Canary traffic splitting.
The Hardware Reality: Context Switching & The Kernel Tax
In a standard mesh (like Istio), every pod has a "Sidecar" proxy. When Service A talks to Service B, the packet follows this path:
App A->OS Kernel->Sidecar Proxy ASidecar Proxy A->OS Kernel->Network FiberNetwork Fiber->OS Kernel->Sidecar Proxy BSidecar Proxy B->OS Kernel->App B
Every time the packet moves between the "App" (User-Space) and the "Proxy" (User-Space), it actually travels through the Kernel-Space. This requires a Context Switch.
- Latency: Each switch adds 0.5ms-1ms. In a complex call chain, this cumulative lag creates "Micro-Jitter" that is notoriously hard to debug.
- CPU Cost: Proxies like Envoy are high-performance but still require CPU cycles to parse headers, apply mTLS encryption, and manage buffers. In many enterprise clusters, 15%-25% of total CPU is consumed just by the "Networking Tax."
3. Envoy Physics: The Filter Chain & Buffer Management
Most modern service meshes use Envoy as their data plane. Understanding Envoy's "Hardware-Mirror" internals is crucial for high-performance architects.
The L4/L7 Filter Chain
When a packet enters Envoy, it doesn't just "Pass through." It travels through a sequence of filters:
- Listener Filters: Handles the raw TCP connection (TLS termination).
- Network Filters: Operates at Layer 4 (TCP/UDP). This is where rate-limiting and RBAC usually reside.
- HTTP Filters: This is where the magic (and the cost) happens. Envoy must parse the HTTP headers to make routing decisions. This is CPU intensive.
Buffer Management & Backpressure
If Service B is slow, Service A's Envoy sidecar will start "Buffering" requests.
- The Risk: If Envoy's memory buffers reach their limit (High Watermark), it will start dropping packets or, worse, crash the pod due to an Out of Memory (OOM) event.
- The Fix: Professional architects set strict
circuit_breakersandmax_requestslimits per connection pool to ensure Envoy sheds load before it consumes the host pod's resources.
4. Intelligent Traffic Control: Beyond Load Balancing
A service mesh transforms the network from a "Pipe" into an Orchestrator.
A. canary Deployments (Header-Based Routing)
Instead of a simple 90/10 split, you can route based on metadata.
- Logic: If
User-Agentcontains "InternalTester" ORx-beta-groupheader is "True," route to Version 2.0. - Benefit: You can test new code in production with real data, but only for specific users, with zero risk to the general public.
B. Fault Injection (Chaos as a Service)
How do you know if your timeout logic works? Use the mesh to proactively fail.
- Delays: Force 5 seconds of latency on 1% of requests.
- Aborts: Force 500 errors on 0.5% of requests. If your application crashes when the network is slow, your architecture is not resilient. The mesh allows you to "Bake" resilience into the infrastructure rather than the code.
5. Security Hardening: SPIFFE/SPIRE & Workload Identity
In a legacy network, security was based on IP Addresses. In a modern mesh, security is based on Identity.
What is SPIFFE?
SPIFFE (Secure Production Identity Framework for Everyone) provides a standard for identifying services regardless of where they run.
- The SVID: Every pod receives a SPIFFE ID and a short-lived X.509 certificate.
- Workload Identity: When Service A talks to Service B, they don't look at IPs. They look at the
Subject Alternative Name (SAN)in the certificate. - Zero Trust: If Service C (a compromised pod) tries to talk to Service B, Service B will reject the connection because Service C does not have a cryptographically valid identity from the mesh's Control Plane.
6. eBPF: The "Proxyless" Future (Cilium)
In 2026, the industry is moving toward eBPF-based networking to solve the Networking Tax.
- The Concept: Instead of a sidecar proxy sitting "next" to the app, we inject the networking logic (mTLS, Retries, Filtering) directly into the Linux Kernel.
- The Physics: By running at the kernel level, we bypass the User-Space context switch entirely.
- The Result: A massive reduction in networking latency and a massive reduction in RAM usage. You no longer need 1,000 Envoy proxies running in your cluster; you just need one kernel module per node.
4. Observability: The Distributed Trace Tax
One of the biggest benefits of a mesh is Distributed Tracing.
- The Internal: When a request enters the Gateway, it is assigned a
trace-id. - The Proxy's Job: The Sidecar automatically injects this
trace-idinto every outgoing HTTP header. - The Architect's Logic: This allows you to generate a "Request Map" of your entire company. If a user's request is slow, you can see exactly which service (and which specific proxy) caused the $200$ms delay.
5. Security: mTLS at Scale
The #1 reason companies install a mesh is mTLS (Mutual TLS).
- Hardware Requirement: For mTLS to be efficient, your hardware should support AES-NI (Intel) or ARMv8 Cryptography Extensions.
- Architecture: The Service Mesh manages "Certificate Rotation" automatically every 24 hours. This means that even if a hacker steals a certificate from a specific pod, it becomes useless within a day. This is the foundation of Workload Identity.
6. Summary: The Interconnect Checklist
- Gateway for Humans, Mesh for Machines: Use your API Gateway for OAuth/Rate-Limiting external users. Use your Mesh for mTLS and internal retries.
- Monitor Context Switches: If your CPU
systime is higher than yourusertime, your sidecar architecture is likely the bottleneck. - Audit the Call-Chain Depth: Avoid chains longer than $4$ hops. If a request passes through $8$ sidecars, the cumulative "Proxy Tax" will destroy your P99 latency.
- Consider eBPF Early: If you are starting a high-performance project in 2026, look at Cilium before installing a traditional sidecar mesh like Istio.
- Telemetry Offloading: Configure your proxies to send logs to a dedicated "Observability Sink" (Review Module 59) so the Logging traffic doesn't compete with the Application traffic.
Service Mesh architecture is the "Nervous System" of the distributed cloud. By understanding the physical cost of the proxy and the emerging power of the kernel-level network, you can build systems that are both indestructible and high-performance. You graduate from "Connecting services" to "Architecting the Global Medium of Intelligence."
Phase 69: Interconnect Actions
- Measure the "Overhead Percentage" of your sidecars: compare local latencies with and without the mesh enabled.
- Implement a Global Rate Limit at your API Gateway to prevent "Noisy Neighbor" attacks.
- Research Cilium Service Mesh for a "Sidecar-less" networking future.
- Review the SPIFFE Runtime Environment to see how workload identities are issued in your cluster.
Read next: FinOps for Architects: Engineering for Cloud Unit Economics ->
Read next: FinOps for Architects: Engineering for Cloud Unit Economics ->
Part of the Software Architecture Hub - engineering the infrastructure of the future.