Space-Based Architecture: High-Scale Concurrency for Enterprise Applications
Learn Space-Based Architecture (SBA): processing units, in-memory data grids, messaging grids, data replication, and how SBA eliminates database bottlenecks for extreme-scale systems.
Space-Based Architecture: High-Scale Concurrency for Enterprise Applications
Most architectures hit a ceiling when concurrent users reach tens of thousands: the database becomes the bottleneck. Adding application servers helps CPU throughput but they all contend for the same database. Space-Based Architecture (SBA) breaks this ceiling by eliminating the database from the high-concurrency path entirely-data lives in distributed in-memory grids that are replicated across processing units, and the database is only an asynchronous persistence target.
The name comes from tuple space computing: data is written to a shared "space" accessible to all processing units, without tight coupling between producers and consumers.
Why Traditional Architectures Hit a Wall
Typical N-tier architecture under load:
10,000 concurrent users
-> 10,000 requests to application servers (scale horizontally ✓)
-> 10,000 database queries (cannot scale horizontally ✗)
Database connection limits:
PostgreSQL: ~200 connections per instance
10,000 requests -> 9,800 requests queued -> latency explodes
Adding read replicas helps reads, but not writes.
Sharding helps writes, but adds complexity and can't do cross-shard joins.The database bottleneck is structural. Throwing hardware at it has diminishing returns.
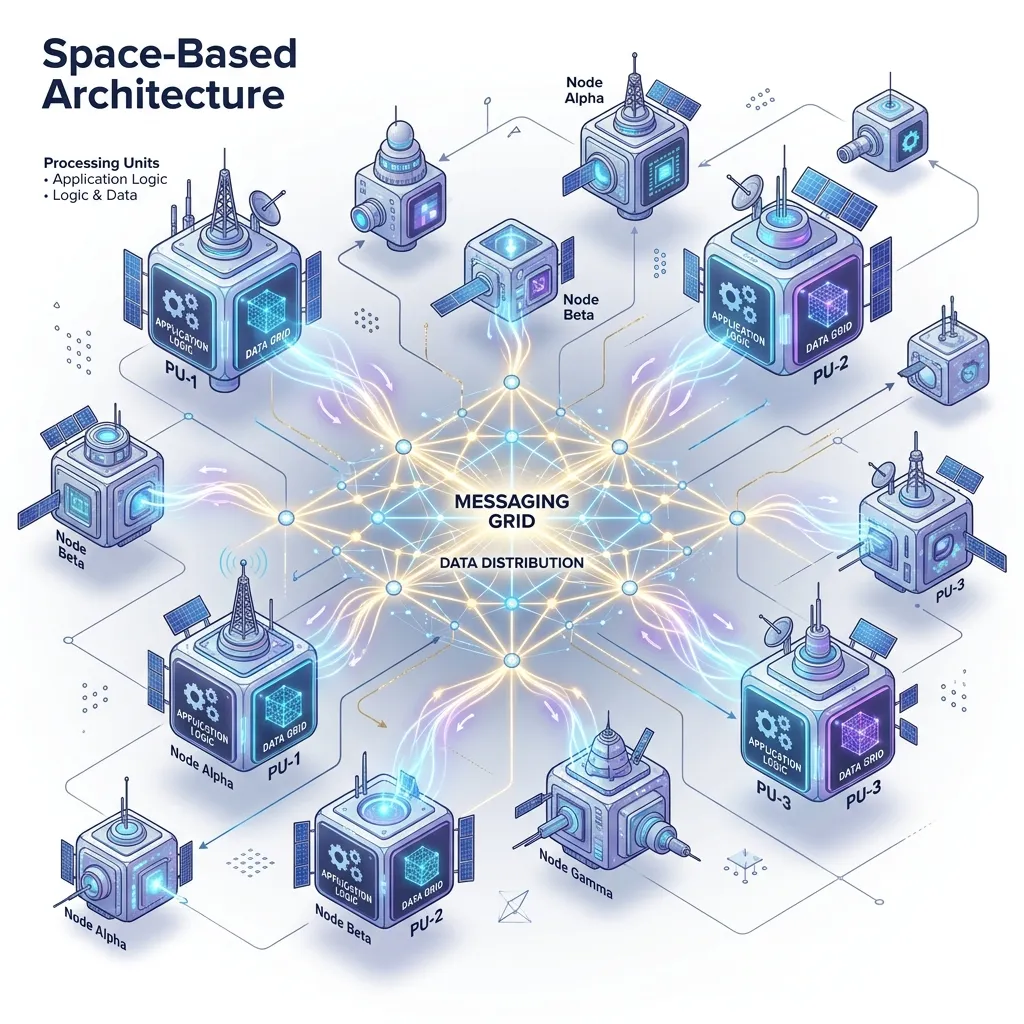
Space-Based Architecture Components
+-----------------------------------------------------+
| Processing Unit (PU) |
| +--------------+ +----------------------------+ |
| | Application | | In-Memory Data Grid (IMDG) | |
| | Logic |←->| (local partition of data) | |
| +---------------+ +-----------------------------+ |
| ←• messaging |
+------------------------------------------------------+
←‘ ←‘
PU 1 PU 2 (identical, different data partition)
Shared infrastructure:
+-----------------------------------------------------+
| Messaging Grid (async event bus between PUs) |
| Virtualization/Middleware (routing, load balancing) |
| Data Grid (distributed IMDG coordinator) |
+------------------------------------------------------+
Persistence layer (async, not on hot path):
+-----------------------------------------------------+
| Database writers |
| Database (PostgreSQL, Cassandra) |
+------------------------------------------------------+Processing Unit (PU)
A self-contained module containing both application logic and its own in-memory data partition. A PU for an order system holds the orders data for users A-M; another PU holds N-Z.
Each PU can handle requests for its data partition entirely in memory-no database call required for reads or writes within the partition.
In-Memory Data Grid (IMDG)
The distributed in-memory store that holds the application's working data. Popular implementations:
| Product | Language | License |
|---|---|---|
| Apache Ignite | Java | Open source |
| Hazelcast | Java | Community + Enterprise |
| Redis Cluster | C | Open source |
| Oracle Coherence | Java | Commercial |
| GemFire (VMware Tanzu) | Java | Commercial |
Data is partitioned across PUs using consistent hashing. Each entry has a primary copy on one PU and backup copies on N others (configurable replication factor).
Implementation with Hazelcast
Hazelcast is the most accessible open-source IMDG for Java. Processing units join a Hazelcast cluster and share distributed data structures.
// Processing unit startup
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.map.IMap;
import com.hazelcast.config.Config;
public class OrderProcessingUnit {
private final HazelcastInstance hz;
private final IMap<String, Order> orders;
private final IMap<String, UserSession> sessions;
public OrderProcessingUnit() {
Config config = new Config();
config.setClusterName("production");
// Configure data partitioning and replication
config.getMapConfig("orders")
.setBackupCount(1) // 1 synchronous backup
.setAsyncBackupCount(1) // 1 async backup
.setEvictionConfig( // evict LRU when memory > 80%
new EvictionConfig()
.setEvictionPolicy(EvictionPolicy.LRU)
.setMaxSizePolicy(MaxSizePolicy.USED_HEAP_PERCENTAGE)
.setSize(80)
)
.setTimeToLiveSeconds(86400); // 24h TTL for order data
// Near cache: per-node local cache for hot reads
config.getMapConfig("sessions")
.getNearCacheConfig()
.setTimeToLiveSeconds(300)
.setMaxIdleSeconds(60);
this.hz = Hazelcast.newHazelcastInstance(config);
this.orders = hz.getMap("orders");
this.sessions = hz.getMap("sessions");
}
// Write to in-memory grid (no database call)
public Order createOrder(CreateOrderRequest request) {
Order order = Order.create(request.getUserId(), request.getItems());
// Atomic put-if-absent (distributed)
if (orders.putIfAbsent(order.getId(), order) != null) {
throw new DuplicateOrderException(order.getId());
}
// Publish event for async DB write and downstream consumers
publishEvent(new OrderCreatedEvent(order));
return order;
}
// Read from memory - sub-millisecond
public Optional<Order> getOrder(String orderId) {
return Optional.ofNullable(orders.get(orderId));
}
// Distributed lock for critical sections
public void confirmOrder(String orderId) {
// Lock prevents two PUs from confirming the same order simultaneously
var lock = hz.getCPSubsystem().getLock("order:" + orderId);
lock.lock();
try {
Order order = orders.get(orderId);
if (order == null) throw new OrderNotFoundException(orderId);
order.confirm();
orders.put(orderId, order);
} finally {
lock.unlock();
}
}
}Messaging Grid: Async Communication Between PUs
The messaging grid decouples PUs and handles cross-PU operations asynchronously.
// Event publishing via Hazelcast topic
public class EventBus {
private final HazelcastInstance hz;
public void publish(DomainEvent event) {
hz.getTopic(event.getTopicName()).publish(event);
}
public <T extends DomainEvent> void subscribe(
String topic,
MessageListener<T> listener
) {
hz.getTopic(topic).addMessageListener(listener);
}
}
// Async database writer - listens for events and persists asynchronously
@Component
public class OrderPersistenceWorker {
@PostConstruct
public void start() {
eventBus.subscribe("order.created", message -> {
OrderCreatedEvent event = message.getMessageObject();
// Write to database asynchronously (not on hot path)
orderRepository.save(event.getOrder());
});
eventBus.subscribe("order.confirmed", message -> {
OrderConfirmedEvent event = message.getMessageObject();
orderRepository.updateStatus(event.getOrderId(), OrderStatus.CONFIRMED);
});
}
}Data Replication and Partition Strategy
Hazelcast partitioning with 271 partitions (default):
4 PU nodes, each owns ~67 partitions
Each partition has 1 primary copy + 1 backup
Partition assignment by consistent hashing of key:
key "order:abc123" -> hash -> partition 142 -> PU node 2 (primary), PU node 3 (backup)
Node joins/leaves: only ~1/N of partitions migrate// Custom partition strategy to co-locate related data
// All of a user's orders go to the same partition
public class UserAwarePartitionStrategy implements PartitioningStrategy {
@Override
public Object getPartitionKey(Object key) {
if (key instanceof String orderId && orderId.startsWith("order:")) {
// Extract userId from "order:{userId}:{uuid}"
return orderId.split(":")[1];
}
return key;
}
}
// Apply to map config
config.getMapConfig("orders")
.setPartitioningStrategyConfig(
new PartitioningStrategyConfig(UserAwarePartitionStrategy.class.getName())
);With co-location, all orders for user "u123" are on the same PU. Cross-partition operations (a user's order list) become single-node reads with no network hop.
Handling Node Failures
Failure scenario:
4 PU nodes, replication factor = 1 (1 primary + 1 backup)
PU Node 2 fails:
1. Hazelcast detects failure via heartbeat (default: 5 seconds)
2. Partitions from Node 2 promoted from backup to primary on Node 3
3. New backups created on remaining nodes
4. Traffic continues - brief pause during promotion (~200ms)
5. When Node 2 restarts, it rejoins and receives its partitions back// Listen for partition events
hz.getPartitionService().addMigrationListener(new MigrationListener() {
@Override
public void migrationStarted(MigrationEvent event) {
log.info("Partition {} migrating from {} to {}",
event.getPartitionId(), event.getOldMember(), event.getNewMember());
}
@Override
public void migrationCompleted(MigrationEvent event) {
metrics.increment("partition.migration.completed");
}
@Override
public void migrationFailed(MigrationEvent event) {
alerts.fire("Partition migration failed: " + event.getPartitionId());
}
});Scaling Up and Down
// Elastic scaling: new PU joins and receives its share of partitions
// Kubernetes horizontal pod autoscaler works naturally with Hazelcast
// HPA configuration in Kubernetes
/*
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: order-processing-unit
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: order-pu
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: External
external:
metric:
name: hazelcast_owned_partition_count
target:
type: AverageValue
averageValue: "30" # scale up when each node owns > 30 partitions
*/When Space-Based Architecture Makes Sense
| Criterion | Verdict |
|---|---|
| > 10,000 concurrent users | Strong fit |
| Latency SLA < 1ms | Strong fit |
| Read/write ratio ≈ 50/50 | Strong fit |
| Data fits in cluster RAM | Required |
| Strong consistency required | Caution (SBA trades consistency for speed) |
| Complex SQL queries/joins | Poor fit (use CQRS with a query store) |
| Small team | Poor fit (operational complexity is high) |
| Existing RDBMS system | Incremental adoption possible |
SBA vs. Microservices vs. CQRS
Microservices: independent services, each with own DB
Problem: still hits DB bottleneck per service at high load
CQRS: separate read/write models
Problem: eventual consistency, but DB is still the write bottleneck
SBA: in-memory state, async DB writes
Advantage: removes DB from hot path entirely
Cost: operational complexity, memory costs, eventual persistence
Best combined pattern:
SBA for high-concurrency write path (order creation, session management)
CQRS read model (Elasticsearch, PostgreSQL) for complex queries
Event sourcing for audit trail and replayFrequently Asked Questions
Q: What happens to data in the IMDG if all nodes crash simultaneously?
Data in the IMDG that hasn't been persisted to the database is lost. This is a fundamental trade-off of SBA: the DB is the source of truth, and the IMDG is a working cache. Mitigation strategies: (1) Use Hazelcast Persistence (Hot Restart) to persist IMDG state to disk-on restart, data is loaded back from disk before accepting traffic; (2) Ensure the async database writer has low latency (< 1 second behind events); (3) Design operations to be idempotent so replaying the event log from Kafka can rebuild state. Full cluster crashes are very rare with proper infrastructure.
Q: How does SBA handle cache invalidation between PUs?
It doesn't need to-there's no central cache to invalidate. Each PU owns a specific partition of data (the primary copy). When data changes, the primary updates and synchronously replicates to backup nodes. No other PU holds a stale copy of that data because the partitioning ensures only one PU is the primary. Near caches (per-node local caches for reads) can become stale, but Hazelcast's near cache invalidation protocol automatically invalidates entries on write.
Q: Is SBA appropriate for financial systems where every write must survive?
SBA can work for financial systems with proper configuration. Use synchronous replication (backupCount >= 2) so writes are acknowledged only after at least two nodes confirm. Enable Hazelcast Persistence to write IMDG state to durable storage. Use a two-phase approach: write to IMDG synchronously, write to database synchronously within the same logical transaction boundary (not async). This sacrifices some throughput but gives ACID-like guarantees. For the most critical financial operations (ledger entries), consider whether the throughput gains justify the operational risk.
Q: How does SBA compare to just using Redis as a cache in front of a database?
"Redis as cache + database" is a much simpler pattern and should be your starting point. It handles most applications up to ~50,000 requests/second with proper indexing. SBA is warranted when: (1) your write throughput exceeds what a single database can handle even with caching, (2) you need sub-millisecond write confirmation (Redis cache-aside doesn't help writes), or (3) your data working set exceeds what a single Redis node can hold. SBA is significantly more complex to operate and debug-choose it deliberately, not by default.