Data Mesh vs Data Fabric: Choosing the Right Modern Data Architecture
Complete guide to Data Mesh vs Data Fabric architectures. Understand why centralised data lakes fail at scale, implement Data Mesh's four principles (domain ownership, data as a product, self-serve infrastructure, federated governance), design a Data Product with SLAs and schemas, compare Data Fabric's AI-driven metadata approach, evaluate the real implementation costs of each, and understand which architecture fits your organisation size and data maturity.
Data Mesh vs Data Fabric: Choosing the Right Modern Data Architecture
Table of Contents
- Why Centralised Data Fails at Scale
- Data Mesh: The Four Principles
- Principle 1: Domain Ownership of Data
- Principle 2: Data as a Product
- Principle 3: Self-Serve Data Infrastructure
- Principle 4: Federated Computational Governance
- Designing a Data Product: Practical Example
- Data Fabric: The Intelligent Integration Layer
- The Real Comparison: When to Use Each
- Implementation Costs: What You're Actually Signing Up For
- Frequently Asked Questions
- Key Takeaway
Why Centralised Data Fails at Scale
The traditional Data Warehouse / Data Lake model works until it doesn't:
The failure modes:
- Bottleneck: Every new data source requires the central team. With 50 domain teams and 10 data engineers, each domain waits 4-8 weeks for pipeline work.
- Knowledge gap: The central team doesn't understand what "Order Status = 'PENDING_FRAUD_CHECK'" means in the context of the Orders domain - so they can't clean or document it correctly.
- Quality degradation: When data breaks, the domain team says "the data team should fix it"; the data team says "the domain team should fix it." Nobody fixes it.
- Schema rigidity: A centralised schema designed for yesterday's needs can't be changed without downstream breakage across all consumers.
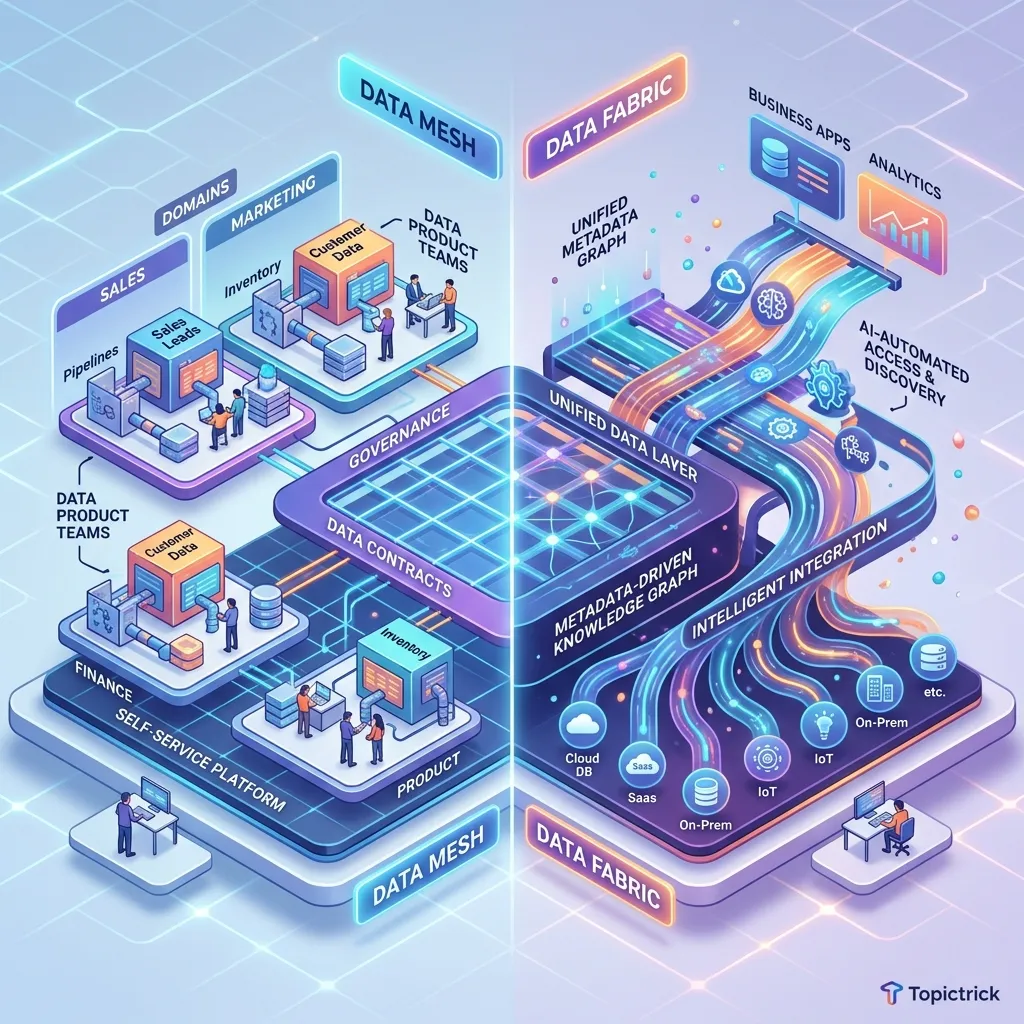
Data Mesh: The Four Principles
Proposed by Zhamak Dehghani (ThoughtWorks) in 2019, Data Mesh is an architectural and organisational paradigm that applies microservices thinking to data:
"If you decentralise applications (microservices), you must also decentralise the data management that supports them."
Principle 1: Domain Ownership of Data
Each domain team owns both their operational systems AND their analytical data products:
Before Data Mesh: After Data Mesh:
Orders Team: Orders Team:
Owns: orders-service Owns: orders-service
Does NOT own: orders data ALSO owns: orders data product
Central Data Team: Central Data Platform Team:
Owns: All ETL pipelines Owns: Self-serve infrastructure tools
Owns: All data in data lake Does NOT own domain data itselfThe Orders team knows exactly what order_status = 'PROCESSING' means, when it changes, and what edge cases exist. They are the correct owners of data quality for order data.
Principle 2: Data as a Product
Domain teams publish data as explicit products with the same quality standards as software products:
| Data Product Attribute | Description | Example |
|---|---|---|
| Discoverable | Listed in a central data catalog | Searchable by name, domain, schema |
| Addressable | Stable, versioned access path | s3://data-mesh/orders/v2/daily/ |
| Self-describing | Schema + documentation inline | dbt docs, OpenAPI-style data schemas |
| Trustworthy | SLA on freshness and accuracy | "Updated within 1 hour of source, 99.9% uptime" |
| Interoperable | Standard formats | Parquet + Avro schema, dbt compatible |
| Secure | Policy-enforced access | Column-level masking for PII |
Designing a Data Product: Practical Example
# data-product-manifest.yaml - Orders Data Product
name: orders-daily-summary
version: "2.0.0"
owner: orders-team@company.com
domain: commerce
description: |
Daily order summary aggregated by status, region, and SKU.
Source of truth for finance reconciliation and logistics planning.
# SLAs:
sla:
freshness: "data available within 60 minutes of end-of-day"
availability: "99.5% uptime"
accuracy: "< 0.01% error rate vs source orders database"
# Access:
output_ports:
- type: object_storage
uri: "s3://data-mesh-prod/orders/daily-summary/v2/"
format: parquet
partitioned_by: [date, region]
- type: query_api
uri: "https://data-api.company.com/orders/daily-summary"
auth: oauth2
# Schema (versioned - breaking changes = version bump):
schema:
- name: date
type: date
required: true
- name: region
type: string
enum: [EU, US, APAC]
- name: order_count
type: integer
description: "Total completed orders in this region for this date"
- name: gross_revenue_gbp
type: decimal(15,2)
description: "Total revenue before refunds, in GBP"
- name: return_rate
type: decimal(5,4)
description: "Fraction of orders returned (0.0 - 1.0)"This manifest is committed to the Orders team's repository. Changes go through pull request review. Version bumps are communicated to data consumers.
Principle 3: Self-Serve Data Infrastructure
Domain teams cannot own data products if they must write low-level ingestion code from scratch for every product. The platform team provides self-serve tooling:
Self-Serve Data Platform provides:
+-- Data ingestion templates (dbt models, Spark jobs, Flink connectors)
+-- Schema registry (Avro / Protocol Buffers / JSON Schema)
+-- Data catalog with auto-discovery (OpenMetadata, DataHub, Amundsen)
+-- Data quality framework (Great Expectations, dbt tests)
+-- Access control automation (column-level masking, row-level filtering)
+--- Monitoring templates (SLA dashboards, pipeline health alerts)
Domain team workflow:
1. Define data product schema in manifest
2. Write dbt model using platform templates
3. Platform auto-provisions pipeline, tests, catalog entry, access controls
4. Domain team monitors SLA via embedded dashboardWithout self-serve infrastructure, Data Mesh devolves into "every domain reinvents their own data pipeline" - worse than the monolithic approach.
Principle 4: Federated Computational Governance
Global policies (security, privacy, compliance) applied locally by each domain without requiring a central team to manually enforce them:
# Global policy: PII columns must be masked for non-authorized readers
# Applied automatically by the platform to every data product:
# Policy definition (global, owned by governance team):
{
"policy": "pii-masking",
"applies_to": "columns tagged: pii",
"permitted_roles": ["data-science-lead", "compliance-officer"],
"others": "mask with SHA-256 hash"
}
# Domain team applies tag in schema - platform enforces policy automatically:
schema:
- name: customer_email
type: string
tags: [pii] # Platform auto-applies masking policy - domain team doesn't manage this
- name: order_total
type: decimal
# No pii tag - readable by all consumersData Fabric: The Intelligent Integration Layer
Where Data Mesh is an organisational solution (change who owns data), Data Fabric is a technological solution (connect data where it already lives):
Data Fabric doesn't move data - it creates virtual, unified access over data that stays in its source systems. AI/ML automatically discovers relationships between datasets, generates metadata, and suggests joins.
The Real Comparison: When to Use Each
| Factor | Data Mesh | Data Fabric |
|---|---|---|
| Primary driver | Ownership & organisational bottleneck | Discovery & access across legacy silos |
| Implementation type | Organisational (culture + tooling) | Technological (buy or build integration layer) |
| Team structure needed | Domain teams with embedded data capability | Central data/platform team |
| Time to first value | 6-18 months (culture change) | 3-6 months (connect existing systems) |
| Ideal organisation | Fast-growing, cloud-native, 100+ domain engineers | Enterprise with decades of legacy data silos |
| Data quality owner | Domain teams | Central data team (unchanged) |
| Scales to 1000+ data sets? | Yes (distributed ownership) | Harder (metadata management becomes complex) |
Frequently Asked Questions
Can we implement Data Mesh without a dedicated data platform team? No. Domain teams will not invest in data product quality if they must also build pipeline infrastructure from scratch for every product. The platform team removes that burden - they provide the common tooling so domain teams can focus on data semantics, not data engineering mechanics. A Data Mesh without a platform team creates 50 incompatible pipeline implementations, which is worse than the centralised baseline.
Is Data Mesh applicable to a company with 20 engineers? No. Data Mesh is designed for organisations where the central data team cannot keep pace with the volume and diversity of data sources across many domain teams. At 20 engineers, a single data engineer with a good dbt project and Redshift or BigQuery provides all the scalable data infrastructure you need. Data Mesh introduces organisational complexity that generates net-negative value below ~200 engineers.
Key Takeaway
Data Mesh and Data Fabric solve adjacent but distinct problems. Data Fabric is a technology overlay that makes existing data silos queryable through a unified interface - valuable in brownfield enterprise environments with decades of legacy systems. Data Mesh is an organisational paradigm that decentralises data ownership to domain teams - valuable in greenfield cloud-native organisations with rapid domain proliferation. The most sophisticated large-scale organisations use both: Data Fabric as the access and discovery layer, Data Mesh principles to govern ownership and quality. The prerequisite for either is honest assessment of where your data quality failures actually originate - technology or ownership.
Read next: Agentic AI Architecture: Building Multi-Step AI Systems ->
Part of the Software Architecture Hub - comprehensive guides from architectural foundations to advanced distributed systems patterns.